Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
This is a page not in th emain menu
Published:
Each month, I will update my fitness and running progress here. I will also share my thoughts on the progress and any changes I make to my routine.
Published:
It’s the end of 2024 again. In last year’s article, “2024 New Year Resolution,” I mentioned 10 things I wanted to accomplish in 2024.
Published:
自2024年11月起逐漸養成每週運動5至6天的習慣後,逐步開始探索身體肌肉的解剖構造。
Published:
紀錄關於替代役的心得以及我在當替代役時所閱讀的書籍。
Published:
主要目的是紀錄我當初選擇攻讀碩士班的動機,以及在學期間重新考試的經歷。
Published:
At the beginning of last year, I also scheduled ten things I planned for 2023 and a 3-day challenge for myself.
Published:
Hello everyone, the following is my rewind of 2023.
Published:
This post will show you how to set up a machine learning enivorment for windows.
Published:
This is a post about how to rebuild ubuntu 22.04, and install some useful tools.
Published:
Happy new year, everyone👋
Published:
「The Big Apple. The dream of every lad that ever threw a leg over a thoroughbred and the goal of all horsemen. There’s only one Big Apple. That’s New York.」 —— The New York Morning Telegraph, John J. Fitz Gerald, 1921
Published:
「大江東去,浪淘盡,千古風流人物」 NBA 悠久歷史,出現許許多多傳奇,相信籃球迷也都津津樂到 在此不多贅述,只分享我這觀看幾年的心路歷程
Published:
「震懾與驚艷,無數條河流匯聚起,萬馬奔騰」,這是我對尼加拉瓜瀑布的評語,目前生平兩度造訪,第一次的初窺,第二次的領略,讓我大致體驗,無數水花飛濺,迷濛的霧氣環顧四周,那美好的記憶被錄製在腦中。
Summer Internship, Academic Sinica, Institute of Information Science, 2020
Duration: Jul. 2020 - Sep. 2020 (3 months)
Part-time, National Yang Ming Chiao Tung University, Department of Communication Engineering, 2023
Duration: Sep. 2023 - Jan. 2024 (5 months)
Part-time, National Yang Ming Chiao Tung University, Department of Communication Engineering, 2024
Duration: Feb. 2024 - Jun. 2024 (5 months)
Full-time, Ministry of the Interior, 2024
Duration: Sept. 2024 - March. 2025 (6 months)
Full-time, Taiwan Semiconductor Manufacturing Company, Artificial Intelligence Application and Platform Department, 2024
Duration: March. 2025 - Present
Published:
College graduation project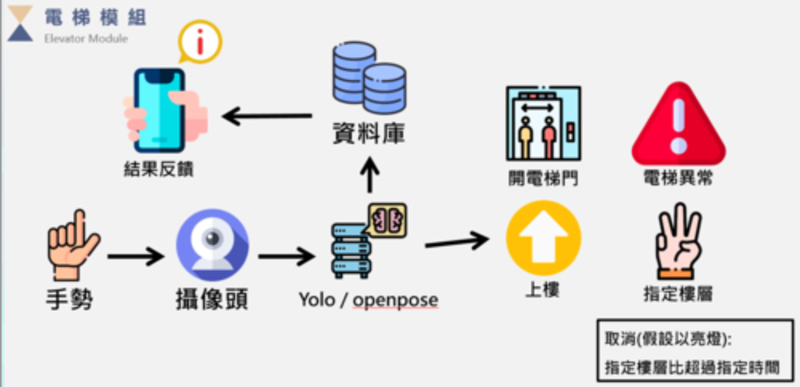
Published:
Graduated project in National Taipei Tech. 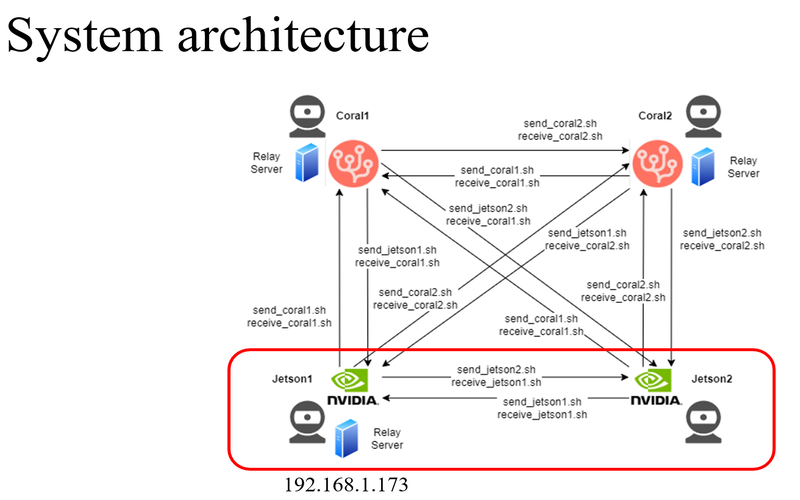
Published:
Team project in National Yang-Ming Chiao-Tung University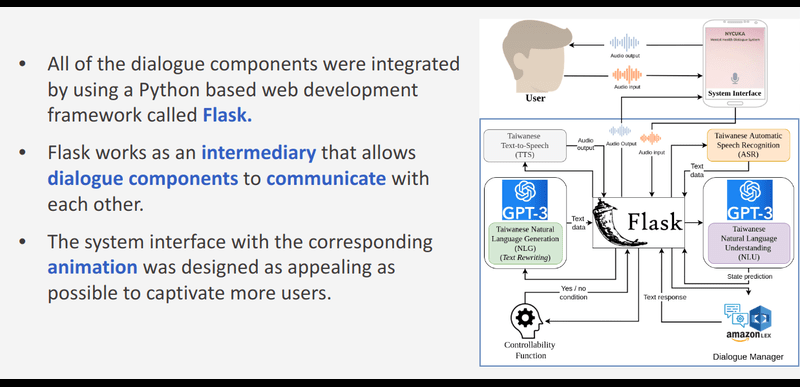
Published:
Personal Side Project
Published:
Personal Side Project
Published:
Course homework
Published:
Master Thesis
Published in NCTU CS Course, 2022
Those are my notes for taking courses
Published in NCTU CS Course, 2023
Those are my notes for taking courses
Published in arXiv, 2023
Using RL to guide language model to generate higher likes comment
Download here
Published in NCTU CS Course, 2023
Those are my notes for taking courses
Published in IEEE Workshop on Automatic Speech Recognition and Understanding, 2023
Mental health chatbot for counselor in university
Download here
Published in NCTU CS Course, 2024
Those are my notes for taking courses
Published in Interspeech, 2024
Prompt tuning with large language model
Download here
Published in O-COCOSDA, 2024
Dataset for student counseling
Download here
Published in 2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2025
A knowledge-infused topic model for empathetic dialogue response
Download here
Published:
Paper presentation for the course called Computer Security in Chang Gung University
Published:
All of my slides which were presented while I was in Taipei Tech.
Published:
Paper presentation for the course called File and Storage system in National Taipei Tech.
Published:
Paper presentation and implemenation for the course called Machine Learning in National Taipei Tech.
Published:
In value-based reinforcement learning methods, function approximation errors are known to lead to overestimated value estimates and sub-optimal policies.
Published:
This paper provide the reader with the conceptual tools needed to get started on research on offline reinforcement learning algorithms:
reinforcement learning algorithms that utilize previously collected data, without additional online data collection.
Published:
Previous methods rely heavily on on-policy experience, limiting their sample efficiency.
They also lack mechanisms to reason about task uncertainty when adapting to new tasks, limiting their effectiveness in sparse reward problems.
This paper developing an off-policy meta-RL algorithm that disentangles task inference and control.
Published:
Motivated by BERT, they turn to the denoising auto-encoding idea to pretrain vision transformers, which has not been well studied by the vision community.
Published:
This paper present SECOND THOUGHTS, a new learning paradigm that enables language models (LMs) to re-align with human values.
Published:
This paper show a method to align language models with user intent on a wide range of tasks by fine-tuning with human feedback.
Published:
This paper proposes HyperPrompt, a novel architecture for prompt-based task-conditioning of self-attention in Transformers.
Published:
In this paper, they first introduce an open-source modular library RL4LMs, for optimizing language generators with RL.
Published:
In this paper, they introduce RL-based DM using a novel mixture of expert language model (MoE-LM) that consists of
Published:
This paper proposes a new algorithm for off-policy reinforcement learning that combines state-of-the-art deep Q-learning algorithms with a state-conditioned generative model for producing only previously seen actions.
Published:
In this paper, they present a comprehensive evaluation of parameter efficient learning methods (PERMs) for generation tasks in natural language processing.
Published:
This study proposes a fine-tuning recipe for retrieval-augmented generation (RAG) models that combine pre-trained parametric and non-parametric memory for language generation.
Published:
Most existing retrieval-augmented LMs employ a retrieve-and-generate setup that only retrieves information once based on the input.
Published:
This paper proposes LLaMA-Adapter, a lightweight adaption method to efficiently finetune LLaMA into an instruction-following model.
Published:
This paper proposes a parameter-efficient fine-tuning method called $\texttt{AdaMix}$, a general parameter-efficient fine-tuning (PEFT) techniques that tunes a mixture of adaptation modules.
Published:
Current SOTA for document retrieval solutions mainly follow an index-retrieve, where the index is hard to be directly optimized for the final retrieval target.
Published:
This paper uses a formal treatment of retrieval-based models to characterize their performance via a novel statistical perspective.
Published:
Nowadays, Generative Pre-trained Transformer models has not only breakthrough performance across complex language modelling tasks, but also by their extremely high computational and storage costs.
Published:
For language models, many methods using teacher forcing (TF) to train.
Published:
In this research, the authors address challenges in empathetic dialogue generation.
Published:
Large language models may generate content that is misaligned with the user’s expectations. For example, generating toxic words, repeated content, and undesired responses for users.
Published:
This paper utilizes a prompt pool to leverage task-specific knowledge and generate instance-specific prompts using attention mechanisms.
Published:
Empathetic dialogue generation task aims at generating empathetic responses, based on perceived emotions instead of definite annotated emotions.
Published:
To improve Reader′ s and Writer′ s for multi-dimensional emotion regression tasks with EMOBANK, this paper proposes an Adversarial Attention Network.
Published:
To reduce the limitation of the large language model, the existing work enhances pre-trained LLMs using grounded knowledge.